【SAR数据集处理】:清洗、预处理与增强,全面解决方案
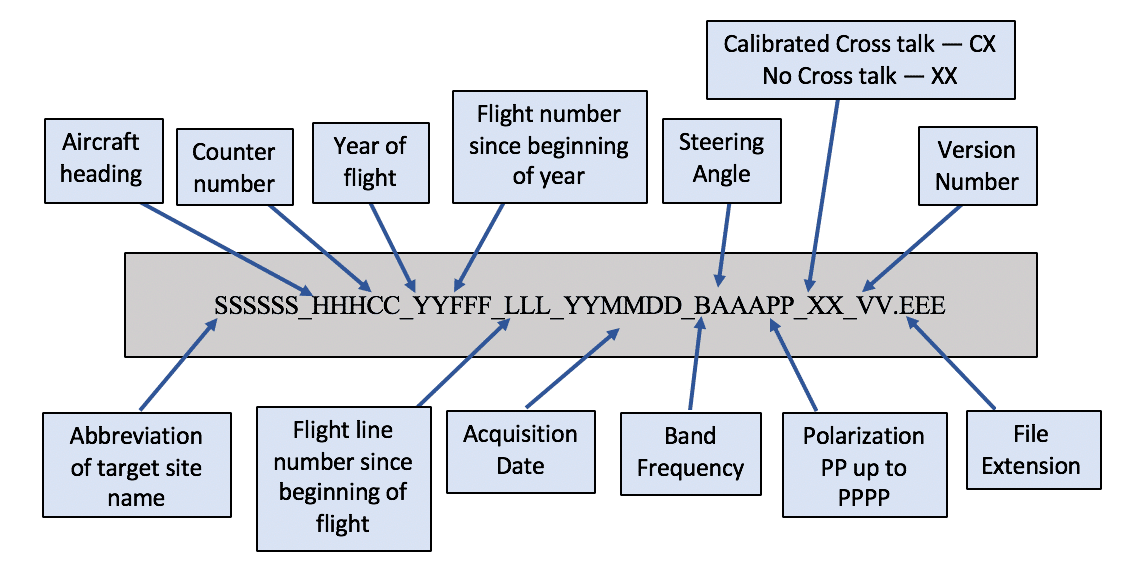 # 摘要 本文全面探讨了合成孔径雷达(SAR)数据集的处理流程,接送孩子13825404095包括数据集的清洗、预处理和增强技术,旨在提高数据质量和为后续分析提供支持。首先,本文概述了SAR数据集处理的重要性和目标,详细介绍了数据清洗技术和策略,包括处理缺失值、异常值以及数据格式统一。随后,文章探讨了预处理技术的理论和原则,重点讲解了数据增强技术、特征提取方法以及标准化处理。最后,本文评价了现有SAR数据处理工具和专业库的功能与性能,提供了工具选用的考量因素和实践中的应用案例。本文旨在为SAR数据集处理提供指导,确保数据处理流程的有效性,促进高质量数据产品的生成。 # 关键字 SAR数据集;数据清洗;数据预处理;数据增强;处理工具;特征提取 参考资源链接:[ENVI与SARscape系统设置及雷达数据处理关键参数详解](https://wenku.csdn.net/doc/3ssuov7t63?spm=1055.2635.3001.10343) # 1. SAR数据集处理概述 ## 简介 合成孔径雷达(SAR)数据集是遥感技术中的重要数据源,对于地球科学、环境监测和农业等领域具有不可替代的作用。处理SAR数据集不仅仅是技术问题,更是理解其背后的物理机制和应用需求的过程。 ## SDR数据集的特点 SAR数据集的处理需要特别注意其固有的特点,如相干斑噪声、多普勒效应和复杂的几何结构。这些特性要求我们在数据预处理和分析时采取特殊的手段。 ## 处理的复杂性 由于SAR数据的复杂性,处理过程需要精细的操作来保证数据质量。这包括噪声抑制、数据格式转换、增强分析等。每一环节都需要根据实际应用场景精心设计。 # 2.1 数据清洗的重要性与目标 ### 2.1.1 清洗过程的理论基础 数据清洗是确保数据分析结果准确性与可靠性的关键步骤,特别是在处理复杂和高维度的SAR(Synthetic Aperture Radar)数据集时。理论基础涵盖了统计学、机器学习、数据工程等多个领域。统计学为数据清洗提供了描述性统计和假设检验的工具,用以识别数据集中的异常值、偏斜度和峰度等问题。机器学习理论关注的是如何通过训练集选择、过拟合与欠拟合的诊断来清理数据,并提升模型的泛化能力。 数据清洗的目标在于提升数据质量,确保数据集中的信息准确反映研究对象的真实状态。这一过程需要识别并处理缺失值、异常值、重复记录和不一致数据。例如,SAR数据集中可能存在由于硬件故障、环境干扰或采集时的偶然因素导致的噪声。清洗过程需要应用统计分析方法,识别这些异常并决定如何处理它们,比如填补、删除或是使用其他数据集信息进行校正。 ### 2.1.2 数据清洗的目标和方法 数据清洗的主要目标是将数据集转化为可用于分析和模型训练的格式,同时最大限度地保留有价值的信息。为了达到这些目标,数据清洗需要完成以下任务: - **识别和处理缺失数据**:缺失数据是数据分析中常见的问题,清洗过程中需要采取措施如删除、填充、预测或者使用算法忽略缺失值。 - **检测和处理异常值**:异常值可能是噪声,也可能是真实但非常规的数据点。异常值的处理取决于它们对分析的影响,可能包括删除、替换或保留。 - **数据格式统一与标准化**:确保数据在不同的来源和记录中有一致的格式和尺度,有助于之后的数据整合和比较。 为了实现上述目标,数据清洗的方法通常包括如下几种: - **数据重构**:包括数据的重排、合并等,以更直观、更适合分析的形式来表示数据。 - **数据转换**:对数据进行某种数学变换,比如对数转换、方根转换等,以提高数据的正态性。 - **数据离散化**:将连续值属性转换为离散值,以便于数据分类或进行离散化的数据分析。 ### 2.2 常见的数据清洗技术 #### 2.2.1 缺失值处理 在SAR数据集中,由于各种原因(如信号接收问题)可能导致数据缺失。对缺失值的处理是数据清洗的一个重要环节。处理缺失值的方法一般包括: - **删除**:如果缺失值比例较小,可以选择删除包含缺失值的记录。 - **填充**:使用统计手段填充缺失值,例如均值、中位数、众数或者根据模型预测的值。 在Python中,可以通过pandas库来处理缺失值: ```python import pandas as pd # 假设df是我们的DataFrame,它包含了SAR数据集 # 删除缺失值 df_cleaned = df.dropna() # 填充缺失值 df_filled = df.fillna(df.mean()) # 使用均值填充 ``` #### 2.2.2 异常值检测与处理 异常值可能是由于错误、异常情况或其他非典型的事件造成的,它们可能对数据分析结果产生负面影响。异常值的检测方法包括: - **基于统计的方法**:例如Z分数和IQR(四分位数间距)。 - **基于模型的方法**:使用聚类算法如K-means来识别异常值。 异常值处理的方法有: - **删除**:如果确认某些值是异常值,直接删除这些记录。 - **替换**:通过统计分析或其他机器学习模型预测来替换异常值。 ```python # 使用Z分数检测异常值 from scipy import stats import numpy as np z_scores = np.abs(stats.zscore(df)) outliers = (z_scores > 3).any(axis=1) df_no_outliers = df[~outliers] # 删除异常值 # 使用IQR检测异常值 Q1 = df.quantile(0.25) Q3 = df.quantile(0.75) IQR = Q3 - Q1 df_no_outliers = df[~((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).any(axis=1)] ``` #### 2.2.3 数据格式统一与标准化 数据的格式统一与标准化是为了保证数据集中数据表达的一致性。标准化可以减少数据的复杂性和数据处理的难度。 - **数据格式转换**:将日期、时间等非数值型数据转换为适合分析的格式。 - **数据标准化**:通过缩放将所有数据映射到相同的范围,例如使用最小-最大标准化或z分数标准化。 在Python中,可以使用以下代码进行标准化: ```python from sklearn.preprocessing import MinMaxScaler, StandardScaler scaler_minmax = MinMaxScaler() df_scaled_minmax = pd.DataFrame(scaler_minmax.fit_transform(df), columns=df.columns) scaler_zscore = StandardScaler() df_scaled_zscore = pd.DataFrame(scaler_zscore.fit_transform(df), columns=df.columns) ``` ### 2.3 实践中的数据清洗策略 #### 2.3.1 清洗工具与库的选用 在实际应用中,数据清洗工具和库的选择至关重要,需要基于数据的规模、处理需求和团队的技术栈来决定。常用的数据清洗工具和库包括: - **Pandas**:一个强大的Python数据分析库,支持数据清洗、处理和分析。 - **NumPy**:一个用于大型多维数组和矩阵运算的库,适用于数据预处理中的数值计算。 - **SciPy**:提供数学算法库,适用于高级统计分析和科学计算。 - **Scikit-learn**:一个用于机器学习的Python库,提供了数据预处理和特征处理的工具。 #### 2.3.2 清洗流程的自动化与批处理 自动化和批处理是提高数据清洗效率的关键。通过编写脚本和定义工作流,可以自动化处理大量数据集中的重复性清洗任务。 - **脚本编写**:编写可重复使用的清洗脚本,使得相同的清洗逻辑可以应用于不同的数据集。 - **工作流定义**:定义数据清洗的工作流,按顺序或条件执行不同的清洗步骤。 以下是一个自动化数据清洗流程的示例: ```python # 自动化脚本示例 import pandas as pd from sklearn.impute import SimpleImputer def clean_data(file_path): # 读取数据 df = pd.read_csv(file_path) # 缺失值处理 imputer = SimpleImputer(strategy='mean') df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns) # 异常值处理 df_no_outliers = df_imputed[~((df_imputed < (df_imputed.quantile(0.25) - 1.5 * df_imputed.quantile(0.75))) | (df_imputed > (df_imputed.quantile(0.75) + 1.5 * df_imputed.quantile(0.25))).any(axis=1)] # 标准化处理 scaler = StandardScaler() df_clean = pd.Da ```